TL;DR: On a Mac, Qwen 3.6 27B is the current top coder if you have 24GB or more RAM (it scores 77.2 on SWE-Bench Verified, ~16GB at Q4). Qwen 3.5 35B-A3B is the efficiency pick: 35B total but only 3B active per token, ~20GB at Q4, and it outscores the 235B Qwen3 on MMLU. Both run via Ollama's MLX backend at roughly 70-80 tok/s on M4. Pick by RAM tier below.
Qwen 3.6 or Qwen 3.5: Which Should You Run on Mac?
Short answer: run Qwen 3.6 27B when your Mac has 24GB or more and you want the strongest current coder. Run Qwen 3.5 35B-A3B when you want maximum quality-per-GB: its Mixture-of-Experts design activates only 3B of 35B parameters, fits ~20GB at Q4, and still outscores the 235B Qwen3 on MMLU.| Your Mac RAM | Best Qwen pick | Why |
|---|---|---|
| 16GB | Qwen 3.5 9B | Largest Qwen that fits comfortably at Q4 (~7GB) |
| 24GB | Qwen 3.6 27B | Current top coder, 77.2 SWE-Bench Verified (~16GB Q4) |
| 32GB+ | Qwen 3.5 35B-A3B | MoE quality, only 3B active per token (~20GB Q4) |
For the full Qwen 3.6 RAM-by-chip table (M1-M5), registry-verified Ollama tags, and MLX speeds, see the dedicated Qwen 3.6 on Mac guide. The rest of this page details the Qwen 3.5 Medium series, the 35B-A3B sweet spot that remains a strong pick for 24GB Macs.
Qwen 3.6 on MacBook Pro and M5 Max: Which Size Fits?
Qwen 3.6 ships in two base sizes for local Macs, each with a standard and a Q8 quantization, four Ollama tags total. All four are registry-verified. Pick by how much unified memory your MacBook Pro has.| Qwen 3.6 model | Quantization | Min RAM | Ollama command |
|---|---|---|---|
| Qwen3.6 27B | Q4_K_M | 24GB | ollama run qwen3.6:27b |
| Qwen3.6 35B-A3B | Q4_K_M | 24GB | ollama run qwen3.6:35b-a3b |
| Qwen3.6 27B (Q8) | Q8_0 | 48GB | ollama run qwen3.6:27b-q8_0 |
| Qwen3.6 35B-A3B (Q8) | Q8_0 | 64GB | ollama run qwen3.6:35b-a3b-q8_0 |
ollama run qwen3.6:27b for the strongest coder, or ollama run qwen3.6:35b-a3b if you want the MoE model's faster responses. Both fit at 24GB, though headroom for long context is tight.
On a 48GB MacBook Pro (M4 Pro, M5 Pro), step up to the Q8 27B (ollama run qwen3.6:27b-q8_0) for near-lossless quality at the same dense-model reasoning depth.
On an M5 Max MacBook Pro, unified memory scales up to 128GB, so every Qwen 3.6 tag in the table above fits comfortably, including the 64GB-minimum 35B-A3B (Q8). That is the quality ceiling for this lineup on a Mac today: ollama run qwen3.6:35b-a3b-q8_0.
Estimated tok/s by chip and quantization, plus the full M1 through M5 breakdown, live on the dedicated Qwen 3.6 on Mac guide.
Alibaba's Qwen 3.5 Medium series remains a masterclass in one thing: smart architecture beats raw parameters. And in April 2026, the Qwen ecosystem has grown even stronger.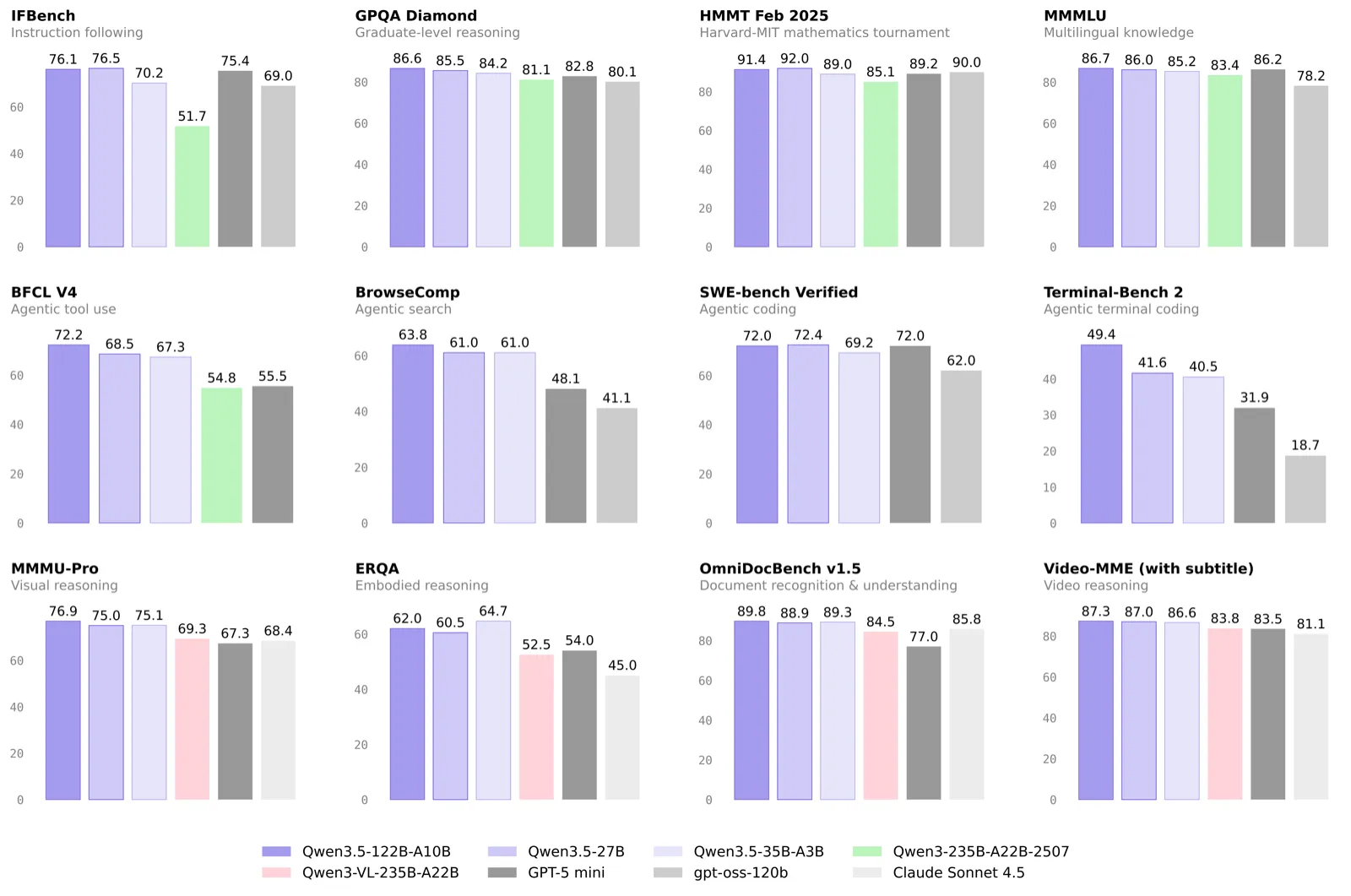 Qwen 3.5: same quality, 7x less RAM than competitors. Chart: Qwen team (Alibaba).
Qwen 3.5: same quality, 7x less RAM than competitors. Chart: Qwen team (Alibaba).
April 2026 Update: Since this article was first published, Alibaba shipped Qwen 3.6-Plus (API-only flagship), Qwen3-Coder-Next (80B MoE coding model you can run locally), four new Qwen 3.5 Small models (0.8B-9B), and Ollama gained MLX support delivering up to 93% faster decode on Apple Silicon. Scroll to the April 2026 Update section for full details.
What Are the Qwen 3.5 Medium Models?
| Model | Total Params | Active Params | RAM Q4 | Context |
|---|---|---|---|---|
| Qwen3.5-Flash | 35B | - | 22 GB | 1M tokens |
| Qwen3.5-35B-A3B ⭐ | 35B | 3B | 20 GB | 128K |
| Qwen3.5-27B | 27B | 27B | 16 GB | 128K |
| Qwen3.5-122B-A10B | 122B | 10B | 72 GB | 128K |
Why Is Qwen3.5-35B-A3B Special?
This model is special.
MoE Architecture: 35B total parameters, only 3B active per token- 35B total, but only 3B active thanks to MoE (Mixture of Experts) architecture
- It beats Qwen3-235B-A22B, a model 7× larger
- It runs on a MacBook Pro M3 24GB (or M4 24GB)
Why Is This Possible?
Alibaba focused on:
- Better architecture (smarter expert routing)
- Data quality (less but better)
- Optimized RL (Reinforcement Learning)
The result: More intelligence with less compute.
How Does It Compare on Benchmarks?
Qwen3.5-35B-A3B vs Qwen3-235B-A22B
| Metric | 35B-A3B | 235B-A22B | Winner |
|---|---|---|---|
| Quality (MMLU) | 82.1% | 79.5% | 35B-A3B ✅ |
| RAM Q4_K_M | 20 GB | ~140 GB | 35B-A3B ✅ |
| Speed (M4 Mac) | ~45 tok/s | ~15 tok/s | 35B-A3B ✅ |
| API Price | $0.002/1K | $0.008/1K | 35B-A3B ✅ |
💡 The model 7× smaller is better, faster, and 4× cheaper.
Which Mac?
| Qwen Model | Minimum Config | Recommended | Speed (pre-MLX) | Speed (Ollama 0.19 MLX) |
|---|---|---|---|---|
| 9B (Small) | MacBook Air M2 8GB | Any Mac 16GB | ~80 tok/s | ~120 tok/s |
| 27B | M2 16GB | M3 24GB | ~55 tok/s | ~85 tok/s |
| 35B-A3B | M3 Pro 24GB | MacBook Pro M4 32GB | ~45 tok/s | ~75 tok/s |
| Flash | M3 Pro 24GB | Mac Studio M4 32GB | ~35 tok/s | ~55 tok/s |
| Coder-Next | Mac Studio M4 64GB | Mac Studio M4 Pro 96GB | ~30 tok/s | ~50 tok/s |
| 122B-A10B | Mac Studio M2 Ultra 96GB | Mac Studio M3 Ultra 96GB | ~30 tok/s | ~45 tok/s |
April 2026 Update: What's Changed
The Qwen ecosystem has expanded significantly since February. Here is everything that matters for Mac users running models locally.
Qwen 3.6-Plus: New API Flagship (April 2, 2026)
Alibaba released Qwen 3.6-Plus on April 2, 2026. It is a closed-source model available only via API (OpenRouter, Alibaba Cloud). Key numbers:
| Metric | Qwen 3.6-Plus |
|---|---|
| SWE-bench Verified | 78.8% |
| Terminal-Bench 2.0 | 61.6 |
| Context Window | 1M tokens |
| Throughput | 158 tok/s |
Qwen 3.6-Plus is competitive with leading closed cloud models on coding benchmarks. Anthropic and OpenAI do not publish decode throughput or parameter counts for Claude Opus 4.5 or GPT-5.4, so a full side-by-side is not possible; the table sticks to Alibaba's published figures.
What this means for local users: Qwen 3.6-Plus is API-only, so you cannot run it via Ollama. The open-weight Qwen 3.5 Medium series remains your best option for local inference. However, 3.6-Plus shows where the architecture is heading. Expect open-weight successors later in 2026.Qwen3-Coder-Next: Best Local Coding Model (March 2026)
Qwen3-Coder-Next is a specialized 80B MoE model with only 3B active parameters, designed specifically for agentic coding. It scores 70.6-71.3% on SWE-bench depending on the scaffold.| Spec | Qwen3-Coder-Next | Qwen3.5-35B-A3B |
|---|---|---|
| Total Params | 80B | 35B |
| Active Params | 3B | 3B |
| Context | 256K | 128K |
| RAM (Q4) | ~46 GB | ~20 GB |
| Best For | Coding agents | General reasoning |
# Run Qwen3-Coder-Next locally
ollama run qwen3-coder-next
Qwen 3.5 Small Models: Tiny but Powerful (March 2026)
Alibaba released four small models on March 2, 2026: 0.8B, 2B, 4B, and 9B. All are natively multimodal (text + image + video), Apache 2.0 licensed, and support 256K context.
| Model | Size (Q4) | GPQA Diamond | MMMU-Pro | Best For |
|---|---|---|---|---|
| Qwen3.5-9B | 6.6 GB | 81.7% | 70.1% | General + vision |
| Qwen3.5-4B | 3.4 GB | - | - | Edge devices |
| Qwen3.5-2B | 2.7 GB | - | - | Lightweight tasks |
| Qwen3.5-0.8B | 1.0 GB | - | - | Embedded / mobile |
The 9B model is remarkable: it edges out GPT-OSS-120B (a model 13x its size) on GPQA Diamond (81.7 vs 80.1). For MacBook Air users with 8GB RAM, the 4B is now a strong recommendation.
# Small models: run on any Mac
ollama run qwen3.5:9b
ollama run qwen3.5:4b
ollama run qwen3.5:2b
ollama run qwen3.5:0.8b
Ollama 0.19 + MLX: Up to 93% Faster on Apple Silicon (March 31, 2026)
This is the biggest quality-of-life update for Mac users. Ollama 0.19 now uses Apple's MLX framework natively, delivering:
- 57% faster prefill (time to first token)
- 93% faster decode (tokens per second)
- Smarter unified memory management
- M5/M5 Pro/M5 Max GPU Neural Accelerator support
Note: MLX support in Ollama 0.19 is a preview release. Currently optimized for Qwen3.5 models, with broader model support coming soon.
Updated Qwen Ecosystem Map (April 2026)
| Model | Type | Params | Active | RAM (Q4) | Context | Local? |
|---|---|---|---|---|---|---|
| Qwen3.5-0.8B | Dense | 0.8B | 0.8B | 1 GB | 256K | Yes |
| Qwen3.5-2B | Dense | 2B | 2B | 2.7 GB | 256K | Yes |
| Qwen3.5-4B | Dense | 4B | 4B | 3.4 GB | 256K | Yes |
| Qwen3.5-9B | Dense | 9B | 9B | 6.6 GB | 256K | Yes |
| Qwen3.5-27B | Dense | 27B | 27B | 16 GB | 128K | Yes |
| Qwen3.5-35B-A3B | MoE | 35B | 3B | 20 GB | 128K | Yes |
| Qwen3.5-Flash | MoE | 35B | - | - | 1M | API only |
| Qwen3.5-122B-A10B | MoE | 122B | 10B | 72 GB | 128K | Yes |
| Qwen3-Coder-Next | MoE | 80B | 3B | 46 GB | 256K | Yes |
| Qwen3.6-Plus | Hybrid | - | - | - | 1M | API only |
Which Model Fits Your Use Case?
Qwen3.5-9B: Best for 8-16GB Macs
- Natively multimodal (text, image, video)
- Matches models 13x its size on reasoning benchmarks
- Ideal for: Vision tasks, general chat, lightweight coding, edge deployment
Qwen3.5-Flash: Production Agents
- 1M context by default (analyze entire documents)
- Built-in tools (calculator, search, code execution)
- Ideal for: Autonomous agents, advanced RAG, long document analysis
Qwen3.5-35B-A3B: The Sweet Spot
- Near-frontier quality on a standard MacBook
- ~75 tok/s with Ollama 0.19 MLX on M4 Pro
- Ideal for: Coding, complex reasoning, intelligent chatbots
Qwen3-Coder-Next: Dedicated Coding Agent
- 80B MoE with 3B active, 256K context
- 70.6-71.3% on SWE-bench (close to frontier closed models)
- Ideal for: Agentic coding, repo-level tasks, multi-file refactoring
Qwen3.5-122B-A10B: Local Frontier
- GPT-4 / Claude 3.5 level quality
- Requires Mac Studio Ultra
- Ideal for: Enterprise, research, critical tasks
How Do You Run Them?
Via Ollama (Local)
All Qwen 3.5 models are available on Ollama (58 tags, 4.6M+ downloads). Update to Ollama 0.19+ for MLX acceleration on Apple Silicon.
# Small models (any Mac)
ollama run qwen3.5:9b # 6.6 GB, best small model
ollama run qwen3.5:4b # 3.4 GB, great for 8GB Macs
# Medium models (24GB+ Macs)
ollama run qwen3.5:35b-a3b # 20 GB, best perf/RAM ratio
ollama run qwen3.5:27b # 16 GB, dense, reliable for coding
# Large models (Mac Studio)
ollama run qwen3.5:122b-a10b # 72 GB, frontier quality
ollama run qwen3-coder-next # 46 GB, best coding agent
# Tiny models (edge / embedded)
ollama run qwen3.5:2b # 2.7 GB
ollama run qwen3.5:0.8b # 1.0 GB
Tip: On Ollama 0.19+, enable MLX for up to 93% faster decode speeds on Apple Silicon. Check with ollama --version and update if needed.
Note: Qwen3.5-Flash is the hosted production version of the 35B-A3B (Qwen model card). There is no Ollama tag for it. Use the API endpoints below for Flash.
Via Cloud API
- Qwen Chat: chat.qwen.ai
- Alibaba Cloud API: modelstudio.console.alibabacloud.com
- Qwen 3.6-Plus (flagship): Available on OpenRouter
- Qwen3-Coder-Next API: $0.12/M input, $0.75/M output
- Qwen3.5 API: ~$0.002/1K tokens (input)
ModelFit's Picks by Mac Configuration
Here are our picks by Mac configuration. Speeds are ModelFit estimates from chip bandwidth and model size (not measured benchmarks):
MacBook Air M2/M3/M4 8GB
→ Qwen3.5-4B (3.4 GB, ~90 tok/s): Multimodal, surprisingly capable
MacBook Air M3/M4 16GB
→ Qwen3.5-9B (6.6 GB, ~120 tok/s): Beats models 13x its size
MacBook Air M3/M4 24GB
→ Qwen3.5-27B (16 GB, ~85 tok/s): Dense, reliable for coding
MacBook Pro M4 24-32GB
→ Qwen3.5-35B-A3B (20 GB, ~75 tok/s) ⭐ Best all-rounder
Mac Studio M4 64-96GB
→ Qwen3-Coder-Next (46 GB, ~50 tok/s): Best local coding agent
Mac Studio M3 Ultra 96GB+
→ Qwen3.5-122B-A10B (72 GB, ~45 tok/s): Frontier quality
Conclusion
Qwen 3.5 marked a turning point in February 2026, and the ecosystem has only gotten stronger since. The era of "bigger just because" models is over. Well-designed MoE architecture delivers frontier performance with 7x better efficiency.
As of April 2026, the Qwen stack covers every Mac: the 4B for 8GB MacBook Airs, the 35B-A3B for 24GB MacBook Pros, and Coder-Next for Mac Studio coding workstations. Ollama 0.19 with MLX nearly doubles inference speeds, making all of these models feel faster than ever.
For modelfit.io users: The 35B-A3B remains our #1 recommendation for MacBook Pro 24GB. For dedicated coding, add Qwen3-Coder-Next if you have the RAM. And if you are on a budget Mac, the 9B punches far above its weight.
Related: Compare Qwen 3.5 with DeepSeek-V3 in our head-to-head comparison, browse all Qwen models, the best LLM for MacBook guide ranked by RAM tier, or check MacBook Pro and Mac Studio recommendations.Frequently Asked Questions
How does Qwen 3.5-35B-A3B beat models 7x its size?
The MoE (Mixture of Experts) architecture activates only 3B of the 35B total parameters per token. Alibaba focused on smarter expert routing, higher quality training data, and optimized reinforcement learning. The result: 82.1% MMLU with 20GB RAM vs 79.5% for the 235B model needing 140GB.
Can I run Qwen 3.5-35B-A3B on a MacBook Air?
The model needs 20GB RAM in Q4 quantization. A MacBook Air with 24GB can run it, though you may experience some memory pressure with other apps open. A MacBook Pro with 24GB provides a more comfortable experience with active cooling. For 16GB MacBook Airs, use the 9B model instead.
What is the difference between Qwen 3.5 Flash and 35B-A3B?
Flash offers 1M token context (vs 128K for 35B-A3B), making it ideal for analyzing entire documents and codebases. The 35B-A3B delivers higher quality per token for shorter tasks. Both need similar RAM (~20-22GB). Choose Flash for RAG and long documents, 35B-A3B for coding and reasoning.
How fast is Qwen 3.5-35B-A3B on Apple Silicon after the MLX update?
With Ollama 0.19 and MLX enabled, expect approximately 70-80 tokens per second on MacBook Pro M4 with 32GB. Before the MLX update, speeds were around 45 tok/s. The 93% faster decode speed from Ollama's MLX integration makes interactive coding feel nearly instant. The MoE architecture keeps speed high because only 3B parameters compute per token.
Is Qwen 3.5-122B worth the extra RAM over 35B-A3B?
The 122B model scores higher on quality benchmarks (84.8% vs 82.1% MMLU) but needs 72GB RAM and a Mac Studio Ultra. For most users, the quality difference does not justify the 3.5x RAM increase. The 35B-A3B is the practical choice unless you need frontier-level accuracy.
Should I use Qwen3-Coder-Next or 35B-A3B for coding?
Qwen3-Coder-Next scores 70.6-71.3% on SWE-bench and is purpose-built for agentic coding: multi-file refactoring, repo-level tasks, and autonomous debugging. However, it needs 46GB RAM. If you have a Mac Studio with 64GB+, use Coder-Next for dedicated coding work. On a MacBook Pro with 24-32GB, the 35B-A3B handles coding well alongside general reasoning tasks.
What is Qwen 3.6-Plus and can I run it locally?
Qwen 3.6-Plus is Alibaba's new flagship model released April 2, 2026. It scores 61.6 on Terminal-Bench 2.0 and offers 1M context, competitive with leading closed cloud models. However, it is API-only. The weights are not publicly available. For local inference on Mac, the Qwen 3.5 series remains the best open-weight option. Access 3.6-Plus via OpenRouter or Alibaba Cloud.
How does Qwen 3.5-9B compare to larger models?
The 9B model is the standout of the Small series. It edges out GPT-OSS-120B (13x its size) on GPQA Diamond (81.7 vs 80.1), a notable result for a much smaller model, though GPT-OSS-120B stays stronger on harder math benchmarks like HMMT. It runs on any Mac with 8GB+ RAM at over 120 tok/s with MLX. For users who cannot afford 24GB of RAM for the 35B-A3B, the 9B is the clear second choice.
Can I run Qwen 3.6 27B on a MacBook Pro?
Yes. Qwen3.6 27B needs 24GB minimum RAM at Q4 (ollama run qwen3.6:27b), so it runs on any MacBook Pro with 24GB or more unified memory. On a 48GB MacBook Pro, use the Q8 tag (ollama run qwen3.6:27b-q8_0) instead for near-lossless quality. Full RAM-by-chip and MLX speed detail lives on the Qwen 3.6 on Mac guide.
Can an Intel MacBook Pro (i9, 16GB) run Qwen, and how fast is it?
Yes, but slowly. Intel Macs get no Metal GPU acceleration in Ollama: that requires Apple Silicon unified memory, so an i9 MacBook Pro runs models on CPU only. For coding, the right family is Qwen2.5-Coder (often searched as "Qwen 2 coder"): ollama run qwen2.5-coder:7b needs about 4.7GB at Q4 and fits a 16GB machine. Expect single-digit tokens per second on an i9 CPU (ModelFit estimate, not measured), versus roughly 10x that on an M-series Mac. If that feels too slow, drop to ollama run qwen3.5:4b (3.4GB), the newer small model that is much quicker on CPU. For usable local coding speeds, any Apple Silicon Mac with 16GB, even a base M1, outperforms an Intel i9 here.
What Qwen 3.6 model should I run on an M5 Max MacBook Pro?
An M5 Max MacBook Pro scales up to 128GB unified memory, so it comfortably fits every Qwen 3.6 tag, including the Q8 35B-A3B (ollama run qwen3.6:35b-a3b-q8_0, 64GB minimum), the highest-quality quantization in the lineup. For pure coding accuracy, the dense 27B Q8 (ollama run qwen3.6:27b-q8_0) is the alternative top pick.
---
Article originally published February 24, 2026. Last updated April 4, 2026 with Qwen 3.6-Plus, Qwen3-Coder-Next, Qwen 3.5 Small series, and Ollama 0.19 MLX speed improvements. Updated July 2, 2026 with a dedicated Qwen 3.6 MacBook Pro and M5 Max RAM-fit section covering all four registry-verified Ollama tags. Updated July 12, 2026 with an Intel MacBook Pro (i9) answer. Resources:Match this model to a machine that can run it: by RAM tier for Apple Silicon, or by VRAM for an NVIDIA GPU.
The weekly local-AI refresh
New open-weight models, real Apple Silicon benchmarks, and the one model worth running on your Mac this week. Free, one email a week, unsubscribe anytime.
By subscribing you agree to our Privacy Policy and to receive the weekly email. Unsubscribe anytime.
Have questions? Reach out on X/Twitter