 Qwen 3.5 small models bring real AI to every device — from iPhone to MacBook
Qwen 3.5 small models bring real AI to every device — from iPhone to MacBook
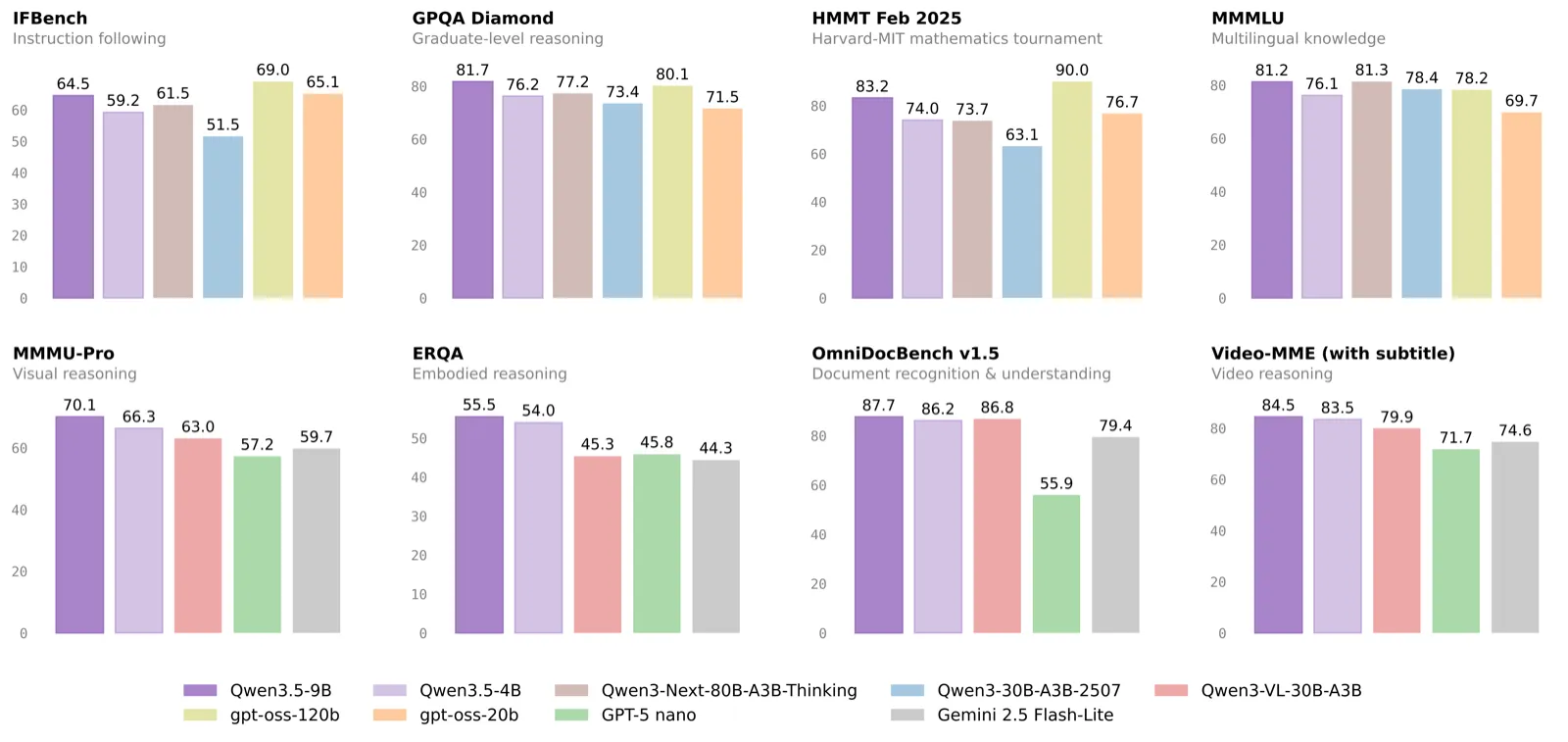
TL;DR: Qwen 3.5 small models (0.8B, 2B, 4B, 9B) deliver outsized performance for their size. The 4B beats 20B-class models at 88.8 MMLU-Redux and fits in 3.5 GB RAM. The 9B hits 91.1 MMLU-Redux, matching models 3-5x larger. All four feature native multimodal vision, 262K context, and 201-language support.
What Are the 4 New Models?
Alibaba released the Qwen 3.5 Small series on March 2, 2026. The announcement reached 7.8 million views and 20,000 likes on X within 48 hours (@Alibaba_Qwen, March 2026). Here is the full lineup.
| Model | Params | RAM (Q4) | Context | Best For |
|---|---|---|---|---|
| Qwen3.5-0.8B | 0.8B | ~0.8 GB | 262K | Mobile, IoT, edge |
| Qwen3.5-2B | 2B | ~1.8 GB | 262K | Edge tasks, fast chat |
| Qwen3.5-4B | 4B | ~3.5 GB | 262K | Coding, agents, multimodal |
| Qwen3.5-9B | 9B | ~7.0 GB | 262K | Quality-first, near-frontier |
All four share the same Qwen 3.5 foundation: Gated Delta Networks with sparse MoE, native vision encoder, scaled reinforcement learning, and support for 201 languages.
How Does the 4B Compare to Larger Models?
The Qwen3.5-4B punches far above its weight class. It scores 88.8 on MMLU-Redux, beating GPT-OSS-20B at 87.8 (HuggingFace benchmarks, March 2026). That is a 4-billion-parameter model outscoring one with 5x more parameters.
| Benchmark | Qwen3.5-4B | GPT-OSS-20B | Qwen3.5-9B |
|---|---|---|---|
| MMLU-Redux | 88.8 | 87.8 | 91.1 |
| GPQA Diamond | 76.2 | — | 81.7 |
| IFEval | 89.8 | — | 91.5 |
| HMMT Feb 25 | 74.0 | — | 83.2 |
| LiveCodeBench v6 | 55.8 | — | 65.6 |
| C-Eval | 85.1 | — | 88.2 |
| TAU2-Bench (agent) | 79.9 | — | 79.1 |
The 9B model hits 91.1 MMLU-Redux, which puts it in the same territory as many 30B+ dense models. Both models score exceptionally on TAU2-Bench (agent tasks), validating Alibaba's claim that these small models can actually run agents — something previously reserved for 14B+ models.
What Architecture Makes This Possible?
The Qwen 3.5 small series uses Gated Delta Networks combined with sparse Mixture of Experts. This architecture activates only the relevant expert pathways per token, reducing compute while maintaining quality (HuggingFace model card, March 2026).
Key specs for the 4B model:
- 2560 hidden dimension, 32 layers, 9216 FFN intermediate
- Native vision encoder built into the model (not bolted on)
- 262,144 native context, extensible to 1,010,000 tokens
- 201 languages supported natively
The native multimodal design is what separates these from competitors like Phi-4 Mini or Gemma 3 4B. You get vision capabilities without needing a separate model or adapter. One model handles text, images, and code.
Which Mac Runs Which Model?
Every Apple Silicon Mac can run at least one of these models. Here is the breakdown by device.
| Device | RAM | Best Qwen3.5 Small | Speed (est.) |
|---|---|---|---|
| iPhone 15 Pro / iPad Pro | 8 GB | 0.8B or 2B | ~60+ tok/s |
| MacBook Air M2/M3 8GB | 8 GB | 2B or 4B | ~80+ tok/s |
| MacBook Air M3 16GB | 16 GB | 4B or 9B | ~70 tok/s |
| MacBook Pro M4 24GB | 24 GB | 9B (plenty of headroom) | ~65 tok/s |
| Mac Mini M4 16GB | 16 GB | 4B or 9B | ~70 tok/s |
The 0.8B and 2B models are small enough to run on-device with Apple's CoreML or MLX frameworks. The 4B model is the sweet spot for 8-16 GB machines — it fits comfortably while delivering benchmark scores that rival 14B models from the previous generation.
Key insight: The Qwen3.5-4B uses only 3.5 GB of RAM at Q4 quantization. That leaves plenty of memory for your IDE, browser, and other apps on a 16 GB MacBook Air.
How to Run Qwen 3.5 Small Models with Ollama
Getting started takes one command per model.
# 0.8B - Ultra-light, mobile-class
ollama run qwen3.5:0.8b-instruct-q4_K_M
# 2B - Fast edge tasks
ollama run qwen3.5:2b-instruct-q4_K_M
# 4B - Sweet spot for coding and agents
ollama run qwen3.5:4b-instruct-q4_K_M
# 9B - Near-frontier quality
ollama run qwen3.5:9b-instruct-q4_K_M
For the best experience on Apple Silicon, consider using MLX or llama.cpp with Metal acceleration. Both frameworks fully support the Qwen 3.5 architecture.
What Can You Actually Build with These?
Reddit users on r/LocalLLaMA have already put these models through real-world stress tests in the first 48 hours after launch.
Qwen3.5-4B highlights:- One user built a complete WebOS web app — with games, text editor, and audio player — from a single prompt (r/LocalLLaMA, March 2026)
- TAU2-Bench score of 79.9 confirms strong agent capabilities — the 4B can plan, use tools, and execute multi-step tasks
- LiveCodeBench v6 score of 55.8 shows solid coding for a model this small
- GPQA Diamond score of 81.7 indicates graduate-level reasoning
- LiveCodeBench v6 at 65.6 means production-quality code generation
- IFEval 91.5 shows excellent instruction following — critical for agent reliability
For context, the larger Qwen3.5-35B-A3B hit 37.8% on SWE-bench Verified Hard with a simple verify-on-edit strategy — near Claude Opus 4.6 at 40% (r/LocalLLaMA, March 2026). The 9B won't match that, but it indicates the architectural improvements benefit models at every scale.
How Do They Compare to Phi-4 and Gemma 3?
The small model space is competitive. Here is how Qwen 3.5 stacks up against similar-sized alternatives.
| Feature | Qwen3.5-4B | Phi-4 Mini (3.8B) | Gemma 3 4B |
|---|---|---|---|
| MMLU-Redux | 88.8 | ~72 | ~74 |
| Native Multimodal | ✅ Yes | ❌ No | ✅ Yes |
| Context Length | 262K | 16K | 32K |
| Languages | 201 | ~25 | ~30 |
| Agent Tasks (TAU2) | 79.9 | — | — |
| RAM (Q4) | 3.5 GB | 3.2 GB | 3.5 GB |
The Qwen3.5-4B wins on every metric except RAM (where it ties with Gemma 3). The 262K context window is 8-16x longer than competitors, and native multimodal support means one model replaces what used to require separate text and vision models.
Which Model Should You Pick?
Choose Qwen3.5-0.8B if:- You need on-device AI on iPhone or iPad
- Latency matters more than quality
- You're building IoT or embedded applications
- You want fast local chat on any Mac
- Edge classification or summarization tasks
- You have 4-8 GB RAM to spare
- You want the best quality-per-GB ratio
- Coding assistance and agent workflows
- You need multimodal (text + vision) in one model
- MacBook Air 8-16 GB is your primary machine
- Quality is your top priority under 10 GB RAM
- You need near-frontier reasoning and coding
- You have 16+ GB RAM available
- You want to replace a 14B model with something faster
Our modelfit.io Recommendation
For most users with a MacBook Air or MacBook Pro, the Qwen3.5-4B is the new default small model. It delivers 88.8 MMLU-Redux in just 3.5 GB of RAM — no other model in this size class comes close.
If you have 16 GB RAM or more, step up to the Qwen3.5-9B for near-frontier quality at 7 GB. It replaces the need for larger 14B models in most tasks.
Check which model fits your exact hardware with modelfit.io — select your device and get personalized recommendations.
FAQ
Can Qwen 3.5 4B really replace larger models?
For many tasks, yes. The 4B scores 88.8 on MMLU-Redux, which exceeds GPT-class 20B models. It handles coding, chat, and agent tasks well. For specialized reasoning or complex multi-step problems, the 9B or larger models still have an edge.
Do these models support vision and images?
Yes. All four Qwen 3.5 small models have a native vision encoder. They can analyze images, read screenshots, and process visual input without needing a separate model or adapter.
What is the maximum context length?
The native context window is 262,144 tokens. With extended attention, it can reach up to 1,010,000 tokens. This is 8-16x longer than competing small models like Phi-4 Mini (16K) or Gemma 3 4B (32K).
Will these run on an iPhone?
The 0.8B and 2B models can run on iPhone 15 Pro and later devices with CoreML or MLX. The 0.8B uses under 1 GB of RAM, making it practical for on-device inference. The 4B may work on devices with 8 GB RAM but leaves limited memory for other apps.
How do these compare to Qwen 3.5 medium models?
The small series (0.8B-9B) fills the gap below the medium series (27B, 35B-A3B, Flash, 122B-A10B). Read our full coverage of the Qwen 3.5 medium series for models that need 16-96 GB RAM.
---
Published March 4, 2026. Models available now on HuggingFace and Ollama. Resources:Match this model to a machine that can run it — by RAM tier for Apple Silicon, or by VRAM for an NVIDIA GPU.
The weekly local-AI refresh
New open-weight models, real Apple Silicon benchmarks, and the one model worth running on your Mac this week. Free, one email a week, unsubscribe anytime.
Have questions? Reach out on X/Twitter