TL;DR: Qwen3.6-35B-A3B is the best local coder for Mac: 73.4 on SWE-bench Verified with only 3B active parameters, fitting a 24GB Apple Silicon machine. Gemma 4 31B matches it on knowledge (85.2 MMLU-Pro) but needs 32GB. On 8-16GB Macs, run Gemma 4 E4B instead.For local coding on a Mac right now, Qwen3.6-35B-A3B is the model to run. It scores 73.4 on SWE-bench Verified while activating only 3B of its 35B parameters per token (Qwen model card, 2026). That sparse design is why it fits a 24GB Apple Silicon Mac and still codes like a model many times its active size. Gemma 4 31B is the strong second pick for general reasoning.
 Qwen3.6-35B-A3B: frontier-level coding from a 3B-active MoE (source: Qwen)
Qwen3.6-35B-A3B: frontier-level coding from a 3B-active MoE (source: Qwen)
A year ago, this level of coding ability meant a 70B+ dense model or a paid API. Now it runs offline on a Mac you may already own. This guide compares the two best open-weight coders you can actually run on Apple Silicon, with every benchmark traced to its primary source.
Which model should you run on your Mac?
The short answer depends on your RAM and your main task. Both are Apache 2.0 licensed, so they are free to use commercially.
| Your goal | Best pick | Command | Min RAM |
|---|---|---|---|
| Local coding agent | Qwen3.6-35B-A3B | ollama run qwen3.6:35b-a3b | 24GB |
| General reasoning | Gemma 4 31B | ollama run gemma4:31b | 32GB |
| Coding on 24GB | Qwen3.6-35B-A3B | ollama run qwen3.6:35b-a3b | 24GB |
| Light Mac (8-16GB) | Gemma 4 E4B | ollama run gemma4:e4b | 8GB |
Qwen3.6 wins on coding and memory efficiency. Gemma 4 31B edges ahead on broad knowledge but needs more RAM for its dense weights.
Why does Qwen3.6 run so well on a Mac?
The answer is its Mixture-of-Experts design. Qwen3.6-35B-A3B holds 35B total parameters but routes each token through just 3B of them. Fewer active parameters means less memory bandwidth per token, and memory bandwidth is the real bottleneck on Apple Silicon.
The practical result: a model that punches at flagship level while loading in about 22GB at Q4_K_M. That fits a 24GB Mac with headroom for your editor and browser.
Qwen3.6 also ships a native 262,144-token context window (Qwen model card, 2026), large enough to hold a full repository in working memory.
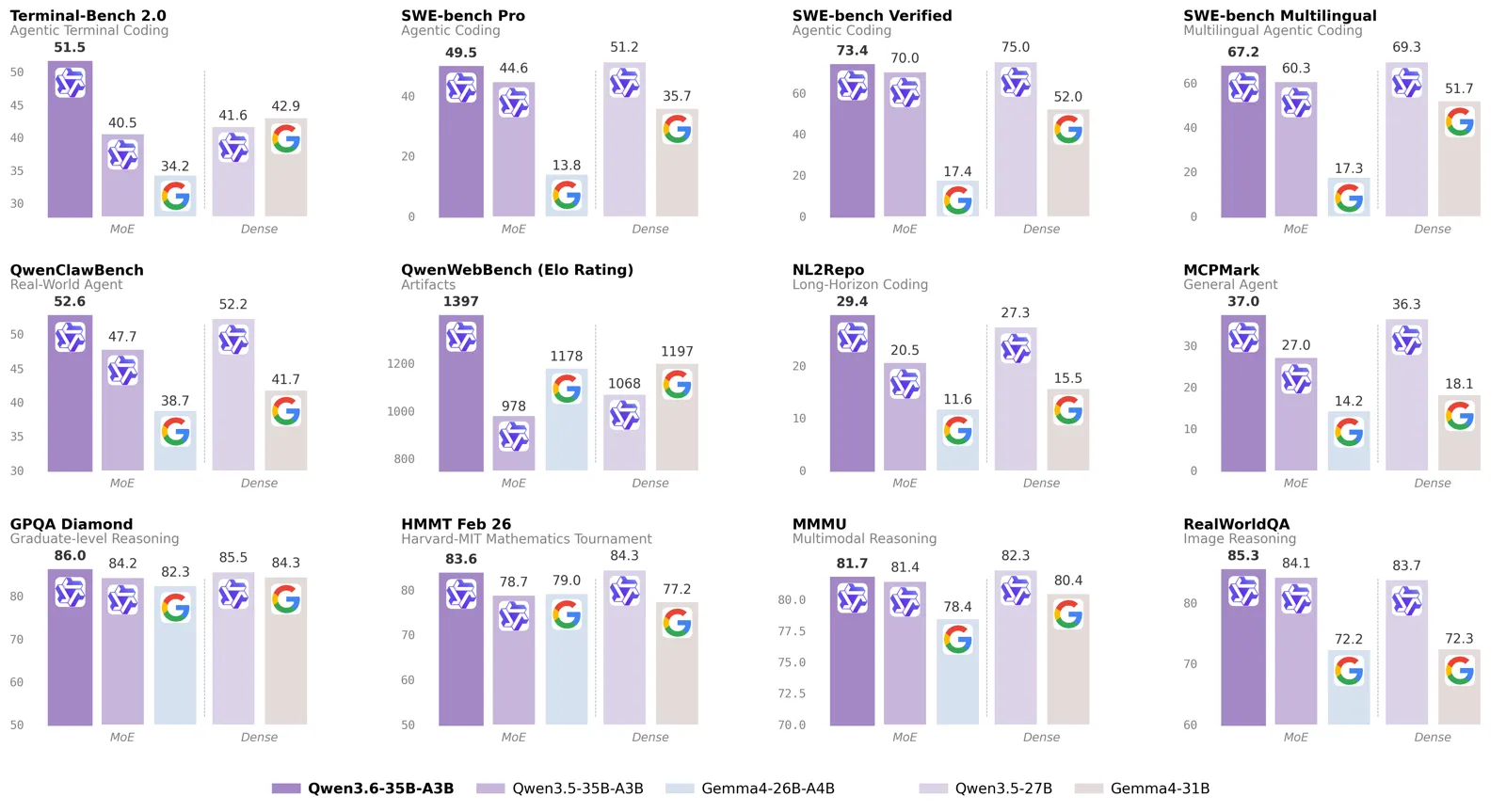
Verified Qwen3.6-35B-A3B benchmarks
Every number below was confirmed against the raw HuggingFace model card, not a summary.
| Benchmark | Score | What it measures |
|---|---|---|
| SWE-bench Verified | 73.4 | Real GitHub issue fixes |
| LiveCodeBench v6 | 80.4 | Competitive coding |
| MMLU-Pro | 85.2 | Broad knowledge |
| GPQA | 86.0 | Graduate science |
| AIME26 | 92.7 | Advanced math |
| SWE-bench Pro | 49.5 | Harder agent tasks |
| Terminal-Bench 2.0 | 51.5 | Shell agent tasks |
Source: Qwen3.6-35B-A3B model card, Apache 2.0, 2026.
How does Gemma 4 31B compare?
Gemma 4 31B is Google's open-weight flagship, and it leads on raw knowledge benchmarks. It matches Qwen3.6 on MMLU-Pro and posts a strong Codeforces rating, but it runs as a dense model, so it asks for more RAM.
Verified Gemma 4 31B benchmarks
| Benchmark | Gemma 4 31B | Gemma 4 26B-A4B |
|---|---|---|
| MMLU-Pro | 85.2% | 82.6% |
| GPQA Diamond | 84.3% | 82.3% |
| LiveCodeBench v6 | 80.0% | n/r |
| AIME 2026 | 89.2% | n/r |
| Codeforces ELO | 2150 | n/r |
Source: Gemma 4 31B model card, Apache 2.0, 2026.
The 26B-A4B variant is Gemma 4's own MoE option. It drops to a 24GB minimum and trades a few points for the lower memory footprint, which makes it the better Gemma choice on a 24GB Mac.
Head to head: the numbers that matter
On coding, the two are close, but Qwen3.6 leads on the agentic SWE-bench test that mirrors real pull-request work.
| Metric | Qwen3.6-35B-A3B | Gemma 4 31B |
|---|---|---|
| SWE-bench Verified | 73.4 | not reported |
| LiveCodeBench v6 | 80.4 | 80.0 |
| MMLU-Pro | 85.2 | 85.2 |
| GPQA | 86.0 | 84.3 |
| Active params | 3B | 31B (dense) |
| Min Mac RAM | 24GB | 32GB |
| Context | 262K | 256K |
The deciding factor for most Mac users is the right column: Qwen3.6 does more with less memory. If you code, start there.
What Mac RAM do you actually need?
RAM is the gate for local models. Here is the fit for each option at Q4_K_M.
| Model | Q4 size | Min Mac RAM | Command |
|---|---|---|---|
| Gemma 4 E4B | ~4GB | 8GB | ollama run gemma4:e4b |
| Gemma 4 26B-A4B | ~16GB | 24GB | ollama run gemma4:26b |
| Qwen3.6 27B | ~18GB | 24GB | ollama run qwen3.6:27b |
| Gemma 4 31B | ~20GB | 32GB | ollama run gemma4:31b |
| Qwen3.6 35B-A3B | ~22GB | 24GB | ollama run qwen3.6:35b-a3b |
The 35B-A3B fitting in 24GB despite its size is the MoE payoff. If your Mac has 32GB or more, you can run any of these comfortably. For a deeper RAM breakdown by chip, see our M5 Pro and M5 Max local LLM guide and the Mac Mini M4 16GB guide.
How to run Qwen3.6 on your Mac
Three steps, fully offline after the download.
1. Install Ollama from ollama.com.
2. Pull and run the model:
ollama run qwen3.6:35b-a3b3. For coding agents, point your editor or Qwen Code at the local Ollama endpoint.
On a 24GB Mac, close memory-hungry apps first. If you hit swap, drop to qwen3.6:27b or the Gemma 4 26B MoE.
Note on vision: Qwen3.6-35B-A3B includes a vision encoder, but the image path has had GGUF issues in some Ollama builds. Text and code work reliably today. Use MLX-VLM if you need the vision features.
FAQ
Is Qwen3.6 better than Gemma 4 for coding?
Yes, for agentic coding. Qwen3.6-35B-A3B scores 73.4 on SWE-bench Verified and edges Gemma 4 on LiveCodeBench (80.4 vs 80.0). Gemma 4 31B is the stronger general-knowledge model but does not report a SWE-bench Verified figure on its card.
Can I run these models on a 16GB Mac?
Not the 31B or 35B versions. On 16GB, run Gemma 4 E4B (ollama run gemma4:e4b), which loads in about 4GB. For a 24GB Mac, Qwen3.6-35B-A3B is the top coder; 32GB unlocks Gemma 4 31B.
Are Qwen3.6 and Gemma 4 free to use?
Both ship under Apache 2.0, which permits commercial use. You download the weights once and run them offline with no API fees.
What does "3B active params" mean?
Qwen3.6-35B-A3B is a Mixture-of-Experts model. It stores 35B parameters but uses only 3B per token. That keeps memory bandwidth low, which is why it runs fast on Apple Silicon while scoring like a much larger model.
Which is faster on Apple Silicon?
The MoE models feel faster per token because they activate fewer parameters. Qwen3.6-35B-A3B and Gemma 4 26B-A4B both benefit from this. Dense Gemma 4 31B is capable but heavier on a Mac's memory system.
The verdict
For local AI coding on a Mac in 2026, Qwen3.6-35B-A3B is the pick: 73.4 on SWE-bench Verified, a 24GB RAM floor, and a 262K context window, all under Apache 2.0. Choose Gemma 4 31B if your priority is broad reasoning and you have 32GB or more. Either way, you get frontier-class help running entirely offline on hardware you control.
Where to Buy for Local AI
best configsRuns 30B models with headroom; active cooling sustains long inference without throttling.
Check price on AmazonMax headroomLoads 70B models locally, the most capable AI laptop config.
Check price on AmazonPrefer to buy direct? Buy from Apple (same price, no affiliate link).
Archive your model library off the internal drive. Quantized models run 5 to 40GB each, so 2TB holds dozens with room to spare.
Check price on Amazon40Gbps external storage fast enough to run models from. Pair it with an M.2 drive for a portable model vault.
Check price on AmazonThe fanless MacBook Air heat-soaks on long inference runs. An aluminum riser lifts the chassis so it sheds heat better off the desk.
Check price on AmazonMore ports for the external drives, displays and peripherals around a local-AI workstation.
Check price on AmazonModelFit may earn a commission on purchases through these links, at no extra cost to you.
Want a Model Bigger Than This Mac Runs? Rent a Cloud GPU
by the hour70B+ and frontier open-weight models that won't fit in unified memory run great on an hourly rented GPU, same open weights, same Ollama workflow, no subscription.
ModelFit may earn a commission on sign-ups made through these links, at no extra cost to you.
The weekly local-AI refresh
New open-weight models, real Apple Silicon benchmarks, and the one model worth running on your Mac this week. Free, one email a week, unsubscribe anytime.
By subscribing you agree to our Privacy Policy and to receive the weekly email. Unsubscribe anytime.
Have questions? Reach out on X/Twitter